Amazon Redshift
Deliver unmatched price-performance at scale with SQL for your data lakehouse
Why Amazon Redshift?
Amazon Redshift powers modern data analytics at scale, delivering up to 3x better price-performance and 7x better throughput than other cloud data warehouses. Redshift Serverless helps you scale analytics workloads effortlessly without managing data warehouse infrastructure. Zero-ETL integrations enable near real-time analytics by easily connecting data from streaming services, operational databases, and third-party enterprise applications without the need for complex data pipelines. Amazon Q in Redshift boosts productivity, simplifying SQL authoring through natural language. Get more accurate output from your generative AI applications by using Redshift as your structured knowledge base in Amazon Bedrock. Redshift seamlessly integrates with the next generation of Amazon SageMaker, allowing you to leverage its powerful SQL analytics capabilities on unified data across the lakehouse in Amazon SageMaker.
Powering the next generation of Amazon SageMaker
Benefits
-
Gain up to 3x better price-performance and 7x better throughput than other cloud data warehouses as you scale your data analytic workloads in Redshift. Reduce costs and meet business critical SLAs by isolating workloads with scalable multi-data warehouse architectures across your organization. With comprehensive security features like network isolation, fine grained access controls such as row level and column level permissions you can protect your data at no additional cost.
Leverage Redshift's powerful SQL analytic capabilities across all of your unified data through its seamless integration in Amazon SageMaker. Query your data in open formats stored on Amazon S3 with high performance, eliminating the need to move or duplicate data between your data lakes and data warehouse. Effortlessly include your Redshift data as part of the lakehouse in SageMaker, opening it up for access by a broad range of AWS and Apache Iceberg-compatible analytics engines and machine learning tools.
-
Innovate faster by making petabytes of data available for analytics without having to build and manage complex pipelines, enabling near real-time access for analytics use cases. Leverage zero-ETL integrations to seamlessly move transactional data from databases like Amazon Aurora, RDS, and DynamoDB into Redshift without performance impact. Ingest high volume real-time data from Amazon Kinesis and Amazon MSK with native streaming services integrations. With all your data in one place, enable near real-time analytics, and build predictive machine learning models directly in Redshift for powerful business insights.
-
Start analyzing your data in a few seconds with Amazon Redshift Serverless. Redshift Serverless learns from your workloads and automatically scales compute to handle your evolving analytic needs, so you can focus on uncovering insights without managing infrastructure. Simply connect to your data sources and start analyzing your data, with no infrastructure set up or maintenance required.
-
Build personalized applications with petabytes of your organizational data through Redshift’s seamless integration with Amazon Bedrock. Boost productivity by enabling data users to more quickly and easily write SQL queries using natural language with Amazon Q generative SQL in Redshift Query Editor. Invoke large language models from Amazon Bedrock and SageMaker for advanced natural language processing tasks like text summarization, entity extraction, and sentiment analysis, to gain deeper insights with your data using SQL.
2025 Gartner Critical Capabilities for Cloud Database Management Systems
AWS ranks among the 2 highest scoring vendors for all analytics use cases.
1st in Event Analytics
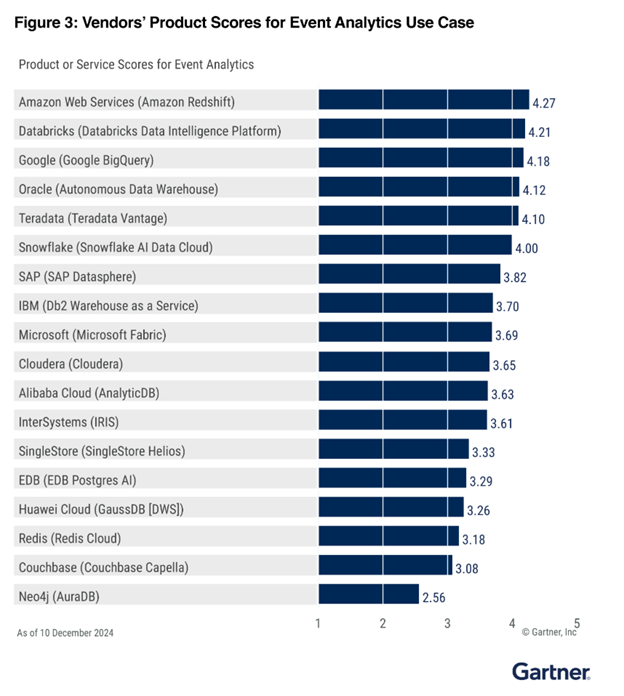
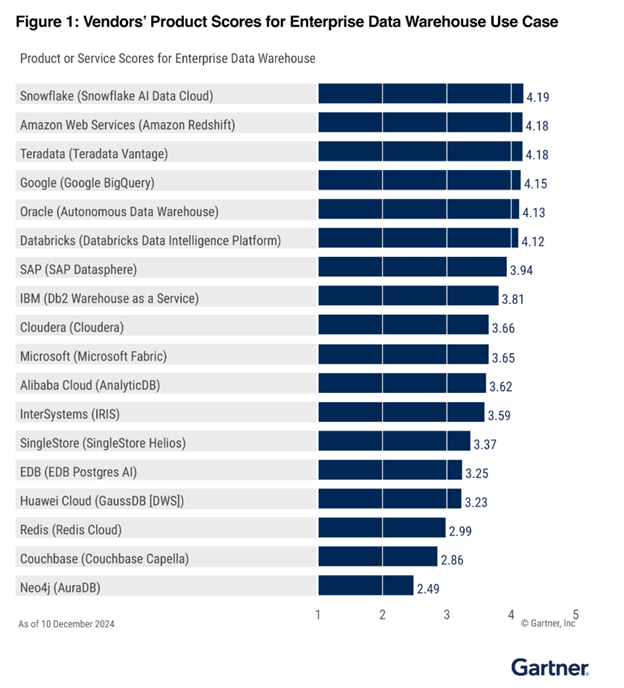
2nd in Enterprise Data Warehouse
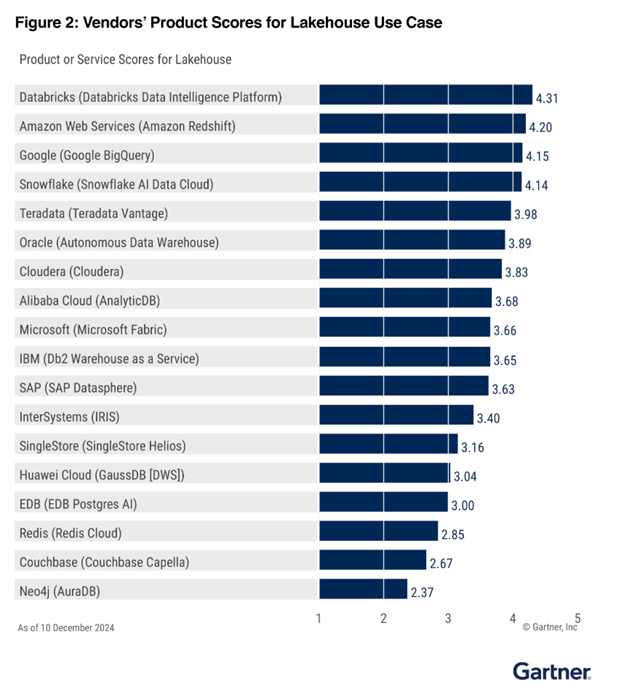
2nd in Lakehouse
Disclaimer
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and is used herein with permission. All rights reserved.
Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner's research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose. This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from AWS.
Use cases
Ingests hundreds of megabytes of data per second so you can query data in near real time and build low latency analytics applications for fraud detection, live leaderboards, and IoT.
Build insight-driven reports and dashboards using Amazon Redshift and BI tools such as Amazon QuickSight, Tableau, Microsoft PowerBI, or others.
Use SQL to build, train, and deploy ML models for many use cases including predictive analytics, classification, regression and more to support advanced analytics on large amount of data.
Build applications on top of all your data across databases, data warehouses, and data lakes. Seamlessly and securely share and collaborate on data to create more value for your customers, monetize your data as a service, and unlock new revenue streams.
Whether it's market data, social media analytics, weather data or more, subscribe to and combine third-party data in AWS Data Exchange with your data in Amazon Redshift, without hassling over licensing and onboarding processes and moving the data to the warehouse.
Amazon Redshift Serverless
Easily run and scale analytics in seconds without provisioning and managing a data warehouse
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages